


Management and administration of servers is the remote administrative care of the client's server infrastructure, located in the cloud or on-premise data center. We know our responsibility, which is why we guarantee the security and continuity of the servers entrusted to us.
Our administrators provide administrative care and manage servers in any location in the world, indicated by the client. The physical location of the administered server does not matter to us, as we are able to manage the infrastructure remotely. We manage both bare-metal (physical) and virtual servers working in any type of virtualization or cloud platform, including: KVM, Xen, VMware, OpenStack, OVHCloud, GCP, AWS, Azure, Hyper-V and bhyve.
We administer and manage any distribution of Linux systems (mostly Ubuntu, Debian, Red Hat, CentOS, Rocky, OpenSUSE) as well as Windows and FreeBSD systems. Our administrators will monitor your infrastructure, detect and quickly resolve encountered problems and prevent them in the future.
How we work
We are vigilant around the clock every day of the year to ensure the uninterrupted operation of the Customer systems. We have developed procedures and monitoring tools that allow us to quickly respond to the irregularities in the operating systems.
In case a failure is reported by the Customer or detected by our monitoring software, we immediately take action to remove it and restore the proper operation of the system, regardless of the time of day.
Why you should have your infrastructure managed by us
We are cost-effective
Maintaining a small to medium infrastructure requires approximately the effort of 5 system administrators, we can maintain your infrastructure for just a fraction of the cost you would spend on system administrators' vacancies.
We are fast
Due to the automation tools and procedures we have developed, we can perform administrative tasks faster and more effectively than someone who does them occasionally.
We are efficient
We know how to optimize your infrastructure to become more efficient and cost-effective. In many cases, there is room for infrastructure optimization - to save space in the rack, to decrease costs of server co-location in the data center, to release additional computing power in your virtualization host operation system, or to improve your server performance.
We are flexible
We will charge you a relatively small amount of money on the monthly basis for our duty and monitoring of the operation of your infrastructure, however, you can order us additional system administration tasks at any time for which you will pay according to the time & material principle.
What we provide
The typical scope of our services includes:
- system packages updates, security patches installation
- operating system hardening (securing services, disabling unused ports, SELinux configuration, etc.)
- firewall configuration (firewalld, iptables, ufw, netfilter-persistent, etc.)
- overall system configuration according to the best practices
- 24/7/365 server monitoring including: response to PING, availability of services, network interfaces configuration, open ports, filesystem usage, resource (CPU, RAM, SWAP) utilization, hard disk and RAID condition.
- response to the failures and detected irregularities in the operating system (system overload, resoure overuse, system overheating) - according to the purchased administrative care level
- installation and configuration of simple system services (i.e.: FTP, SMTP, Apache, Nginx, MySQL/MariaDB, KVM, Docker, etc.), setup of complex applications and software clusters will require additional setup fee
- automatic monitoring of the operating system regarding filesystem changes, traces of potential intrusions and malicious configuration changes
- review and analysis of the system logs
- consulting regarding server and system extensions, modifications, and optimal resource allocations
- user accounts and privileges management (creating, modifying, and deleting accounts, configuring ACLs)
- contacting data center staff and hosting provider where the Customer co-locates / keeps bare-metal or virtual servers in order to fix the system issues and failures
- backup management (manual and periodic backups of applications and databases, backup restore procedures)
How we manage your servers
The procedure of your servers handover to us for administration can be described in a few steps:
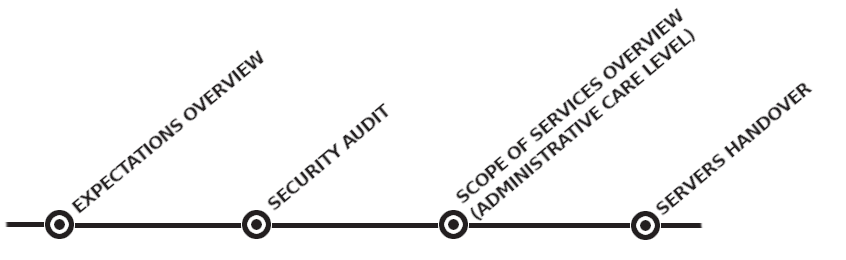
The servers' handover procedure starts with the Customer's expectations overview, then we perform a security audit to assess the security level of the systems. Based on the audit log and Customer expectations we discuss the scope of our services and administrative care level. In the last stage, the servers are handed over to us by the Customer for administration.
Entrusting us with administrative care is associated with giving us administrative access.
Administrative care packages we offer
Our offer includes administrative care over the servers, regardless of the servers location. We provide administrative care in three packages with different response times: Premium, Comfort and Eco:
Premium |
Comfort |
Eco |
|
| Remote servers administration |  |
|
|
| Backups creation | |
|
|
| Server's security and functionality monitoring 24/7/365 | |
|
|
| Failure handling | 24/7/365 | 24/7/365 | MON - FRI 7AM - 5PM (CET) |
| Price / month * | 460 EUR | 380 EUR | 125 EUR |
* the price depends on the size of the administered infrastructure
Response times according to the package
Premium |
Comfort |
Eco |
|
| Critical incident | 30 min | 1 h | 2 h |
| Urgent incident | 2 h | 4 h | 4 h |
| Standard order | NBD | NBD | 2 NBD |
| Technical query | 2 NBD | 2 NBD | 2 NBD |
Planned time to solve the problem from the moment of notification
Premium |
Comfort |
Eco |
|
| Critical incident | 2 h | 4 h | 4 h |
| Urgent incident | 4 h | 4 h | 4 h |
| Standard order | NBD | NBD | 2 NBD |
| Technical query | 2 NBD | 2 NBD | 2 NBD |
NBD - next business day
In Premium and Comfort package time is measured 24 hours a day, in Eco package time is measured from 7 AM to 5 PM in Central European Time Zone
Critical incident - the majority of users are unable to use the main functionalities of the system
Urgent incident - hindered use of the system functionality by the majority of users or the inability to use additional functionalities or the inability to use the main functions of the system by a few users.
Standard order - any case that is not an incident, for example, a configuration of a new service or a reconfiguration of the existing one.
Technical query - a topic related to consultations, answering questions about the operation of systems, statistics, reports, etc.
